대량 데이터 MySQL 튜닝(Indexing) 및 옵티마이저 실행 계획 분석
SQL SELECT 시 데이터 수가 적다면 Query를 어떻게 작성하여도 대부분 큰 문제가 되지 않습니다. 하지만 한 테이블에 대략 100만개의 데이터가 저장되어있다면? 어떤 데이터를 조회할지에 대한 상태에 따라 다르겠지만 소요되는 시간이 급격히 증가 될 것이라는 것은 직감적으로 느낄 수 있습니다.
이번 포스팅에서는 SQL 튜닝이 왜 중요하며 성능을 테스트하기 전 왜 디스크에서 가져오는 것이 속도가 느리며 MySQL의 옵티마이저가 어떠한 실행계획을 작성하는지에 대해 살펴보고 튜닝을 진행해보고자 합니다.
디스크의 읽기 방식
디스크 I/O 작업은 알다시피 비용이 많이 발생하는 작업입니다. 디스크에 있는 데이터를 조회할 때 원판을 생각하면 이해하기 쉬운데 디스크 헤더를 특정 데이터가 있는 원판의 위치로 이동시켜야만 해당 데이터를 읽는다고 간단히 표현하겠습니다. 이러한 디스크 작업에도 두가지의 종류가 있습니다.
랜덤 I/O & 순차 I/O
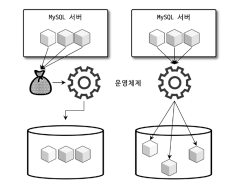
순차 I/O(왼쪽)와 랜덤 I/O(오른쪽) 이미지 출처 - RealMySQL 8.0 1권
그림처럼 가장 위쪽 MySQL 서버에 세개의 데이터가 있으며 톱니바퀴를 MySQL의 옵티마이저라 가정합시다.
| 조회 방식 | 디스크 접근 횟수 |
|---|---|
| 순차 I/O | 1번 |
| 랜덤 I/O | 3번 |
순차 I/O 방식은 찾아야 할 세개의 데이터가 디스크에 정렬되어있다고 가정할 경우 MySQL 서버의 세개 데이터를 주머니에 넣어 옵티마이저에게 부탁하는 것을 예로 들 수 있습니다.
반면 랜덤 I/O 방식은 디스크에 찾아야 할 데이터가 정렬되어있지 않고 중구난방으로 떨어져있기 때문에 디스크에 있는 데이터를 하나하나 찾아가며 조회를 해야합니다.
즉 순차 I/O는 디스크 헤더를 1번 움직인 반면, 랜덤 I/O는 디스크 헤더를 여러번 움직여 찾아야 하기 때문에 3번의 접근이 발생합니다.
해당 내용은 HDD를 기준을 설명하였지만 HDD보다 더욱 빠른 SSD도 마찬가지로 순차 I/O보다 랜덤 I/O가 Throughput(처리량)이 떨어집니다.
위 내용을 한마디로 표현해보자면 ‘디스크에 데이터가 정렬되어있기 때문에 데이터를 빠르게 가져오도록 계획할 수 있다’ 라고 표현할 수 있습니다.
MySQL 옵티마이저
디스크의 조회 방식을 간단히 살펴보았으니 MySQL 엔진의 가장 중요한 옵티마이저에 대해서 간단히 설명하겠습니다.
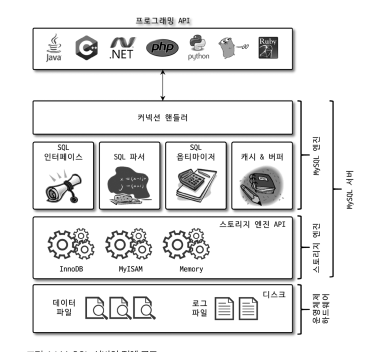
MySQL 전체 구조 이미지 출처 - RealMySQL 8.0 1권
원하는 데이터를 조회하기 위해 MySQL Client가 MySQL 서버에 요청하게 되면 첫번째로 MySQL 엔진을 거치게 됩니다. 이때 엔진에서는 Client가 보낸 SQL Query가 올바른지 검사 후 옵티마이저는 해당 Query를 분석하고 최적화하여 실행계획을 세웁니다. 그 후 핸들러 API를 통하여 MySQL 스토리지엔진 (InnoDB) 로 해당 쿼리를 디스크에 가져오도록 명령합니다.
결국 MySQL 옵티마이저가 세운 계획에 따라 얼마나 효율적으로 데이터를 조회할 지 판단이 되며 SQL Query를 작성하는 개발자는 어떤 순서로 테이블에 접근할지 인덱스를 사용할지 어떤 인덱스를 사용할지를 설정하여 옵티마이저가 설정한대로 계획을 세우도록 유도하는 것이 핵심입니다.
그럼 어떻게 효율적으로 데이터를 조회하도록 유도할 수 있을까요?
Index
인덱스(Index)란?
데이터를 빨리 찾기 위해 특정 컬럼을 기준으로 미리 정렬해놓은 표
위 순차 I/O 에서 정렬되어 있었기 때문에 접근 횟수를 줄일 수 있었습니다. 인덱스(Index) 정의 또한 미리 표를 정렬해 놓는다고 하였는데 결국 위 내용들은 모두 인덱싱을 위한 빌드업이였으며 튜닝의 가장 핵심적인 요소라고 생각합니다.
우선 간단한 예시로 설명하겠습니다.
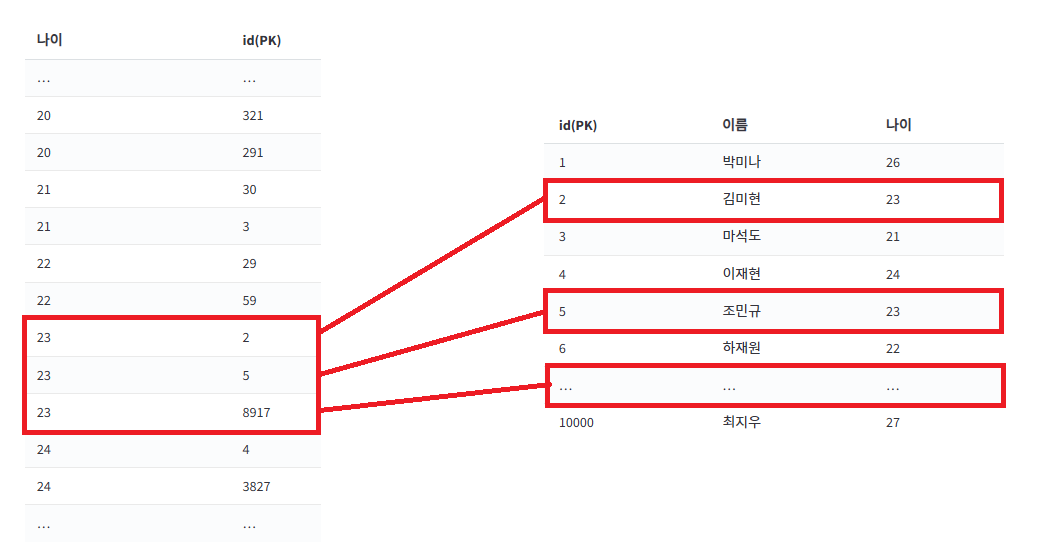
인덱스를 직접 생성하게 되면 우리 눈에는 안 보이지만 위와 같은 표가 시스템 내부적으로 생성됩니다. 나이를 기준으로 정렬해놓은 표를 가지고 있기 때문에, 나이를 기준으로 데이터를 조회할 때 접근 횟수도 줄이며 훨씬 빠르게 찾을 수 있습니다.
인덱스 종류가 다양하지만 자세한 인덱스에 대한 정리는 다른 포스팅으로 작성 계획입니다.
SQL 튜닝 및 실행 계획 분석 ( 기본 )
테스트 테이블의 정보 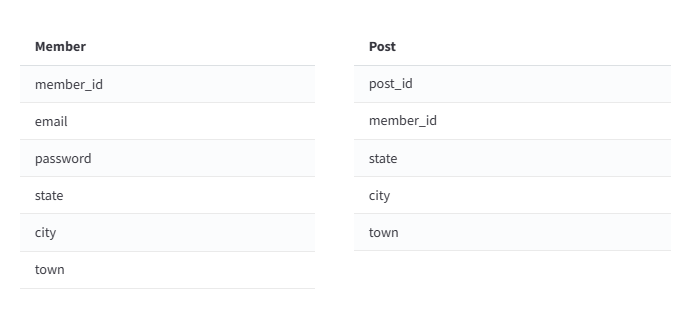
member, post 테이블에 50만건, 100만건 저장
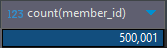
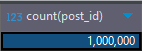
테스트 SQL
1
2
3
4
5
EXPLAIN ANALYZE SELECT * FROM post p
WHERE
p.state='Incheon'
and p.city='mapo'
and p.town='sinsa';
Index 미적용 ( 기본 )
실행 결과
1
2
-> Filter: ((p.town = 'sinsa') and (p.city = 'mapo') and (p.state = 'Incheon')) (cost=100954 rows=994) (actual time=0.0547..1016 rows=2 loops=1)
-> Table scan on p (cost=100954 rows=993592) (actual time=0.0424..968 rows=1e+6 loops=1)


위 실행결과는 옵티마이저가 스스로 판단하여 실행 순서를 정의한 것입니다. rows를 보면 1e+6이라고 적혀있는데 이는 게시물 데이터 100만개로서 풀테이블 스캔을 의미합니다. 또한 실행 결과를 보면 1000ms가 소요된 것을 확인할 수 있습니다.
예제에서는 만약 100만개지만 데이터가 1000만개 아니 1억개라면 어떨까요? 이와 같이 데이터 Size가 늘어날 수록 조회 비용이 더욱 커져 성능이 감소할 것 입니다.
따라서 상황 마다 다르겠지만 위와 같은 상황에선 조건이 간단하기에 WHERE 조건인 state와 city, town에 Multi Column Index를 구성하는 것이 효율적이라고 생각합니다.
Index 적용 ( 기본 )
Index 추가
1
CREATE INDEX idx_state_city_town on post(state, city, town);
실행 결과
1
-> Index lookup on p using idx_state_city_town (state='Incheon', city='mapo', town='sinsa') (cost=0.7 rows=2) (actual time=0.0442..0.0556 rows=2 loops=1)


인덱스를 적용하였기 때문에 아예 디스크로 접근하지도 않고 바로 인덱스 테이블에서만 가져오는 것을 확인할 수 있습니다. 또한 1000ms 에서 0.091ms로 성능이 약 11배 정도 개선되었습니다.
| Index 적용 여부 | 테이블 접근 Type | 속도 |
|---|---|---|
| 미적용 | ALL(풀테이블 스캔) | 1000ms |
| 적용 | Index | 0.091ms |
이는 간단한 예제이기 때문에 문제를 해결하기 수월했지만, 좀더 복잡한 JOIN, GROUP BY 예제를 통하여 조금 더 테스트해보겠습니다.
SQL 튜닝 및 실행 계획 분석 ( JOIN )
테스트 테이블 정보 
users, posts 테이블에 100만건 저장
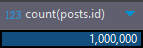
테스트 SQL
1
2
3
4
5
EXPLAIN ANALYZE SELECT p.id, p.title, p.created_at
FROM posts p
JOIN users u ON p.user_id = u.id
WHERE u.name = 'User0000046'
AND p.created_at BETWEEN '2022-01-01' AND '2024-03-07';
Index 미적용 ( JOIN )
실행 결과
1
2
3
4
5
-> Nested loop inner join (cost=152183 rows=11082) (actual time=102..1250 rows=3 loops=1)
-> Filter: ((p.created_at between '2022-01-01' and '2024-03-07') and (p.user_id is not null)) (cost=100473 rows=110816) (actual time=0.0508..954 rows=218410 loops=1)
-> Table scan on p (cost=100473 rows=997442) (actual time=0.0368..265 rows=1e+6 loops=1)
-> Filter: (u.`name` = 'User0000046') (cost=0.367 rows=0.1) (actual time=0.00128..0.00128 rows=13.7e-6 loops=218410)
-> Single-row index lookup on u using PRIMARY (id=p.user_id) (cost=0.367 rows=1) (actual time=0.00104..0.00106 rows=1 loops=218410)

옵티마이저 실행계획
- post 테이블 100만개 중 날짜 조건에 만족하는 게시물을 21만개 rows를 조회한다.
- 앞서 21만개의 게시물 중 user 의 id 기본키 인덱스를 사용하여 name이 User0000046인 레코드를 조회한다.
- Nested loop inner join 으로 Users와 Posts 테이블을 조인하며 3개의 데이터를 필터링한다
개선해야 할 사항
- 날짜 범위 풀테이블 스캔
- 유저 name을 찾기 위한 21만번 loop 반복
Index 적용 ( JOIN )
Index 추가
1
2
CREATE INDEX idx_name ON users (name);
CREATE INDEX idx_created_at ON posts (created_at);
실행 결과
1
2
3
4
> Nested loop inner join (cost=8.85 rows=2.16) (actual time=0.13..0.148 rows=3 loops=1)
-> Covering index lookup on u using idx_name (name='User0000046') (cost=1.1 rows=1) (actual time=0.0184..0.0191 rows=1 loops=1)
-> Filter: (p.created_at between '2022-01-01' and '2024-03-07') (cost=6.02 rows=2.16) (actual time=0.109..0.126 rows=3 loops=1)
-> Index lookup on p using user_id (user_id=u.id) (cost=6.02 rows=19.5) (actual time=0.0895..0.0967 rows=21 loops=1)

옵티마이저 실행 계획
- name 인덱스 설정으로 인한 Covering index로 한번에 u.id를 조회한다.
- posts와 users 를 조인할 때 미리 구해놓은 u.id를 통하여 posts 중 User0000046이 작성한 21개의 게시물 데이터를 가져온다.
- posts의 날짜 조건대로 3개로 필터링한다
실행 결과의 rows를 확인해보면 풀테이블 스캔한 결과는 나타나지 않습니다. 따라서 JOIN 조건이 걸려도 상황에 따라 판단하여 Index를 적절히 조정하는 것이 필요하다고 생각합니다.
| Index 적용 여부 | 테이블 접근 Type | 속도 |
|---|---|---|
| 미적용 | ALL(풀테이블 스캔) | 0.373ms |
| 적용 | Index | 0.131ms |
SQL 튜닝 및 실행 계획 분석 ( GROUP BY )
목표 : 부서별 최대 연봉을 가진 사용자들 조회하는 SQL문 튜닝
테스트 테이블 정보
| User |
|---|
| user_id |
| name |
| department |
| salary |
| created_at |
users 테이블 200만건 저장
테스트 SQL
1
2
3
4
5
6
7
EXPLAIN ANALYZE SELECT u.id, u.name, u.department, u.salary, u.created_at
FROM users u
JOIN (
SELECT department, MAX(salary) AS max_salary
FROM users
GROUP BY department
) d ON u.department = d.department AND u.salary = d.max_salary;
Index 미적용 ( GROUP BY )
실행 결과
1
2
3
4
5
6
7
8
9
-> Nested loop inner join (cost=5.18e+6 rows=0) (actual time=1964..3884 rows=18 loops=1)
-> Filter: ((u.department is not null) and (u.salary is not null)) (cost=201118 rows=1.99e+6) (actual time=0.0948..945 rows=2e+6 loops=1)
-> Table scan on u (cost=201118 rows=1.99e+6) (actual time=0.0939..806 rows=2e+6 loops=1)
-> Covering index lookup on d using <auto_key0> (department=u.department, max_salary=u.salary) (cost=0.25..2.5 rows=10) (actual time=0.00139..0.00139 rows=9e-6 loops=2e+6)
-> Materialize (cost=0..0 rows=0) (actual time=1587..1587 rows=10 loops=1)
-> Table scan on <temporary> (actual time=1587..1587 rows=10 loops=1)
-> Aggregate using temporary table (actual time=1587..1587 rows=10 loops=1)
-> Table scan on users (cost=201118 rows=1.99e+6) (actual time=0.0304..626 rows=2e+6 loops=1)

옵티마이저 실행 계획
- 서브쿼리 조회 결과 도출 (풀테이블 스캔)
- 100만개 조회하며 부서별로 집합하여 10개 결과 도출하고 메모리에 임시 테이블 인덱스 저장
- Covering index 이 부분에서 user 테이블과 각각 비교. ( 레코드 하나 하나 전부 비교 )
- users 테이블에서 department와 salary가 Null이 아닌 값만 가져옴
- 왜 Null 체크를 하여 풀테이블 스캔할까? -> 결과를 도출 할 때 부서가 Null인데 Salary를 가지고 있을 수도 있기 때문
- 서브쿼리 결과와 Null 체크 결과를 조인하여 결과를 도출
개선해야 할 사항
- GROUP BY department는 department를 기준으로 정렬을 시킨 뒤에 MAX(salary) 값을 구하게 됩니다. 이 때, MAX(salary)를 구하기 위해 이리저리 찾아다닐 수 밖에 없습니다.
이를 해결하기 위해 (department, salary)의 멀티 컬럼 인덱스가 있으면 department를 기준으로 정렬을 시키는 작업을 하지 않아도 되고, 심지어 MAX(salary)도 빠르게 찾을 수 있습니다.
Index 적용 ( GROUP BY )
Index 추가
1
CREATE INDEX idx_department_salary ON users(department, salary);
실행 계획
1
2
3
4
5
6
-> Nested loop inner join (cost=12.3 rows=24.7) (actual time=1.16..1.29 rows=18 loops=1)
-> Filter: ((d.department is not null) and (d.max_salary is not null)) (cost=14.3..3.62 rows=10) (actual time=1.13..1.13 rows=10 loops=1)
-> Table scan on d (cost=15.8..18.1 rows=10) (actual time=1.13..1.13 rows=10 loops=1)
-> Materialize (cost=15.5..15.5 rows=10) (actual time=1.12..1.12 rows=10 loops=1)
-> Covering index skip scan for grouping on users using idx_department_salary (cost=14.5 rows=10) (actual time=1..1.11 rows=10 loops=1)
-> Index lookup on u using idx_department_salary (department=d.department, salary=d.max_salary) (cost=0.643 rows=2.47) (actual time=0.0146..0.0159 rows=1.8 loops=10)

옵티마이저 실행 계획
- 서브 쿼리에는 설정한 인덱스 컬럼이 모두 존재하기 때문에 Covering index skip 으로 명시되어있는 것 처럼 빠르게 인덱스를 통하여 레코드 조회
- Materialize 를 통하여 메모리에 임시 인덱스 테이블 저장 ( 재사용을 위함 )
- 저장한 10개의 레코드를 d로 테이블 스캔하고 Null 체크 필터링 수행
- u.id나 u.name 같은 컬럼도 조회해야 하기 때문에 Index lookup 수행.
- 만약 u.department, u.salary 이 두개의 컬럼만 있다면 Covering Index
| Index 적용 여부 | 테이블 접근 Type | 속도 |
|---|---|---|
| 미적용 | ALL(풀테이블 스캔) | 3000ms |
| 적용 | Index | 0.102ms |
마무리하며..
이렇게 SQL Query에 따른 튜닝을 진행해봤습니다. 제가 테스트한 것은 튜닝 방법의 일부일 뿐 상황에 따라 Index를 설정하면 안될 때도 있으며 Index가 아닌 where 조건을 변경한다던지 여러가지 방법이 많은 것 같습니다. 이러한 부분도 테스트 해봤지만 글이 너무 길어질 것 같아 따로 기록하지 못했습니다. 튜닝도 중요하지만 MySQL 아키텍쳐에 대해 더욱 자세히 알아야 더 효율적인 개선이 가능하다고 생각합니다.