CPU, Memory 모니터링을 통한 성능 측정 및 병목현상 원인 파악과 해결 과정
병목현상이란?
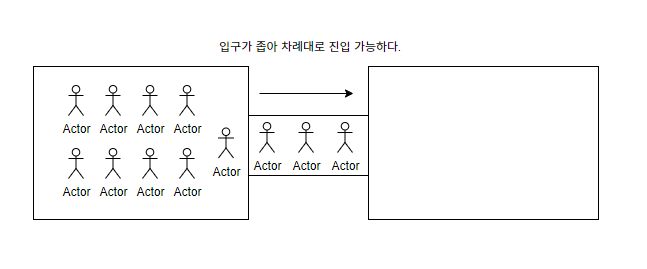
병목현상은 다수의 요청이 동일한 자원이나 시스템으로 몰려 특정 지점에서 처리 용량을 초과하게 되어 발생하는 성능 저하 현상을 의미한다.
이번 포스팅에서는 병목현상의 발생 원인을 시각적 자료와 함께 분석하고, 이를 해결하기 위한 성능 개선 방법을 제시해보고자 한다.
또한, 병목현상을 분석하여 그 원인이 내부 시스템 흐름에 어떻게 영향을 미치는지에 대한 과정도 기록한다.
AWS 테스트 환경 구성
서버 구성 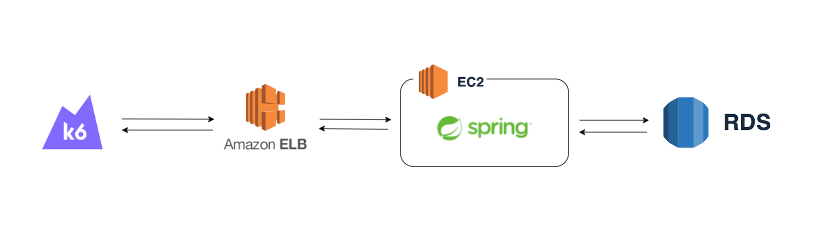
[db.t3.micro] Mysql RDS 20GB 1vCPU, 1GB Mem- 데이터베이스[t3a.small] AWS EC2 WAS 8GB 2vCPU, 2GiB Mem- 애플리케이션 서버 (WAS)[t3a.small] AWS EC2 K6 8GB 2vCPU, 2GiB Mem- K6 부하 생성기AWS ELB(Elastic Load Balancing)- 로드밸런서AWS CloudWatch- 모니터링
RDS 테스트 데이터 구성
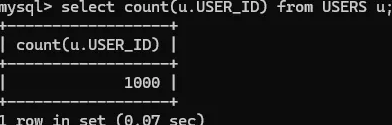
사용자 데이터 1000건
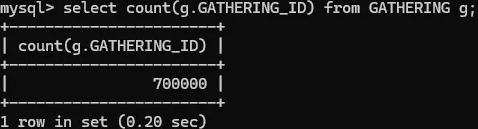
여러 상태의 모임 데이터 70만건
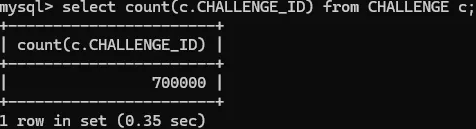
챌린지 데이터 70만건
테스트 시나리오
- AWS 서버 스펙을 낮춰 70만 데이터 량에도 처리 속도를 일부로 늦춤
- 가상 사용자 수(VU)를 10분에 걸쳐 50명으로 설정하여 점진적으로 부하 테스트를 진행
- 95% 확률로 게시물 조회를 요청하고, 5% 확률로 로그인 후 게시물을 생성하는 시나리오
- 사용자는 요청 후 1초간 sleep 후 다시 요청
- K6를 사용한 스크립트를 통해 테스트를 진행
K6 테스트 스크립트
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
import http from 'k6/http';
import { sleep } from 'k6';
export const options = {
// 부하를 생성하는 단계(stages)를 설정
stages: [
// 10분에 걸쳐 vus(virtual users, 가상 유저수)가 50에 도달하도록 설정
{ duration: '10m', target: 50 }
],
};
export default function () {
let random = Math.random();
// 100명 중 5명의 비율로 게시글을 작성
if (random < 0.05) {
// 1. 로그인 요청
const loginPayload = JSON.stringify({
email: 'email1@naver.com',
password: 'Wjdwptk1!',
});
const loginHeaders = { 'Content-Type': 'application/json' };
const loginResponse = http.post('http://{ELB 주소}/api/auths/login', loginPayload, { headers: loginHeaders });
if (loginResponse.status === 200) {
const loginResult = JSON.parse(loginResponse.body);
const token = loginResult?.result?.token; // 토큰 값 추출
const postPayload = JSON.stringify({
name: '제목',
content: '내용',
endDate: '2025-03-13',
startDate: '2025-02-08',
minCapacity: 1001,
maxCapacity: 1002,
bookId: 1,
gatheringStatus: 'RECRUITING',
readingTimeGoal: 'ONE_HOUR',
gatheringWeek: 'ONE_WEEK',
});
const postHeaders = {
'Content-Type': 'application/json',
Authorization: `Bearer ${token}`, // Authorization 헤더 추가
};
http.post('http://{ELB 주소}/api/gathering', postPayload, { headers: postHeaders });
}
// 100명 중 95명의 비율로 게시글을 조회
} else {
http.get('http://{ELB 주소}/api/gatheringSearch/filtering?gatheringSortType=NEWEST_FIRST&page=0&size=10&startDate=2025-01-20&endDate=2025-03-30&readingTimeGoals=ONE_HOUR&today=false');
}
// 1초 휴식을 주어 더 현실적으로 테스트
sleep(1);
}
테스트 측정 결과
Throughput
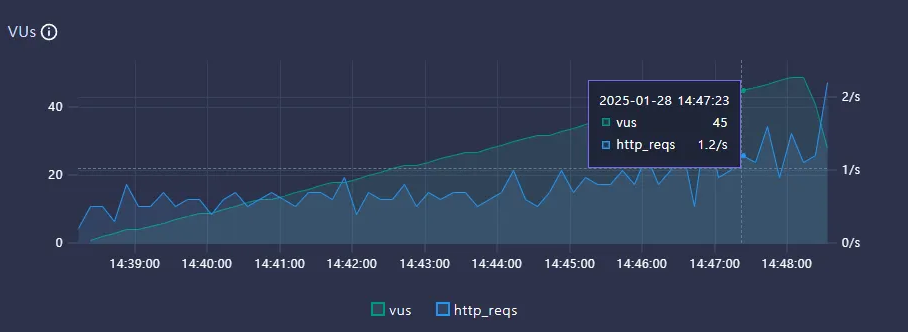
- VUs : 50
- TPS : 1.2/s
Latency

- 평균 요청 비율 : 1.2/s
- 평균 응답시간(Latency) : 46.3/s
HTTP Request Fail

이번 테스트는 50명의 가상 사용자가 동시 요청하는 기준으로 진행되었다. 테스트 결과, 초당 처리 가능한 요청 수(TPS)는 평균 1.2/s 로 측정되었으며, 지연시간(Latency)는 약 46.3/s.
HTTP Request Fail의 수 또한 0.55/s 로 측정되어 전체적으로 많은 트래픽도 아니였지만 현저히 불안정한 테스트 결과가 발생
CPU, Memory 모니터링 측정 결과
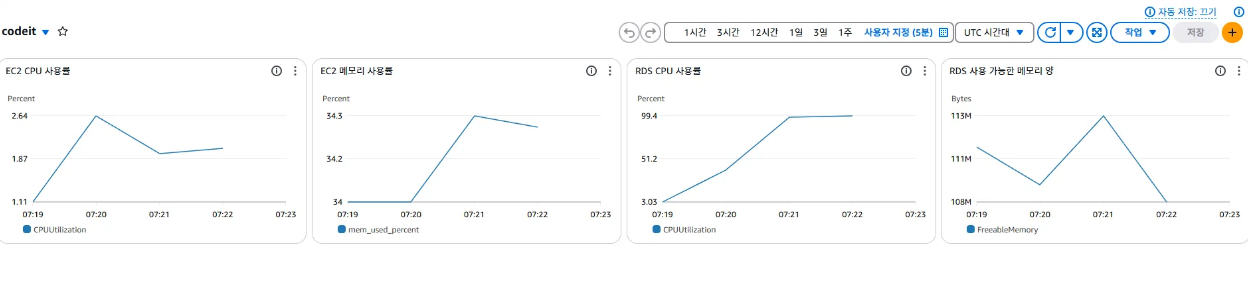
테스트 실행 초기 모니터링 결과, EC2와 RDS의 CPU 및 메모리 사용률이 점진적으로 증가하며 부하 발생 확인. 이 시점 서버와 DB가 균등하게 요청을 처리하고 있음을 파악.
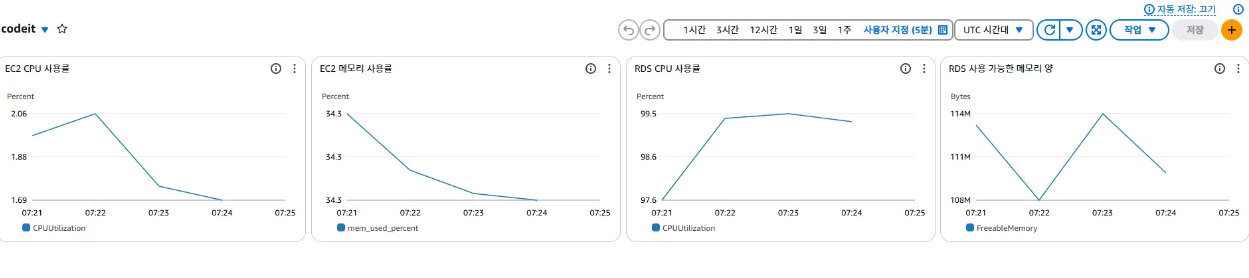
테스트 실행 최종 모니터링 측정 결과 VUs가 증가함에 따라 트래픽이 늘었고, EC2와 RDS의 CPU 사용률이 급격히 차이를 보임 특히, RDS의 CPU 사용률은 99% 가까이 차지하며 DB에서 병목현상이 발생하고 있다는 것을 확인.
RDS 병목 현상 분석 (커넥션 풀 부족)
테스트에서 발생한 오류
1
2
java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 30000ms
(total=10, active=10, idle=0, waiting=1)
| Command | Description |
|---|---|
| total=10 | 커넥션 풀 최대 크기가 10개로 설정됨. |
| active=10 | 10개의 커넥션이 모두 사용 중. |
| idle=0 | 유휴 상태(사용 가능한) 커넥션이 없음. |
| waiting=1 | 새로운 요청이 커넥션을 기다리고 있음. |
| request timed out after 30000ms | 30초 동안 기다렸지만 커넥션을 얻지 못해 타임아웃 발생. |
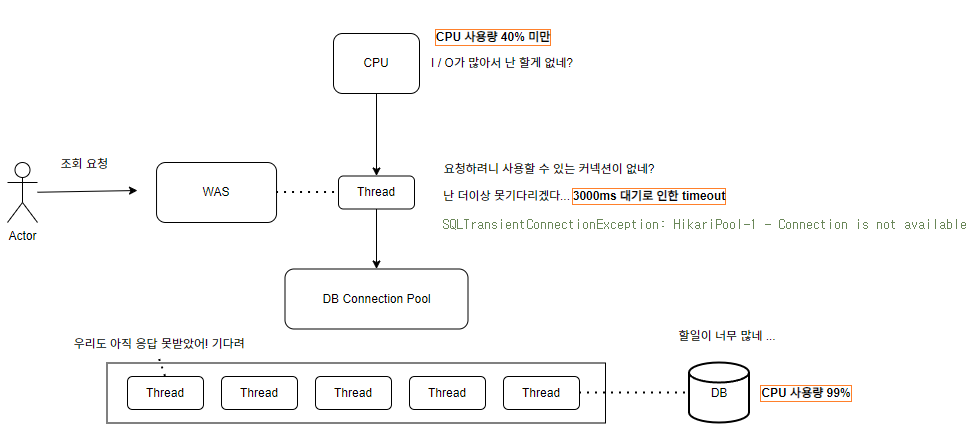
해당 오류는 DB 커넥션 풀로 설정한 최대 크기 10개가 모두 사용 중일 때 새로운 요청이 대기 상태로 오래 머물게 되어 발생한 문제. EC2의 CPU 사용량이 낮고, RDS CPU 사용량이 높았던 것도 이러한 이유 때문.
이로 인해 발생하는 문제
- 동시 요청이 많아질수록 점점 더 많은 스레드가 대기 상태로 쌓임
- 일정 수 이상의 요청이 들어오면 스레드 풀이 가득 차서 새로운 요청을 처리하지 못함
- 결과적으로 응답 지연이 발생하고 서버가 제대로 응답하지 못하는 성능 저하 현상이 발생
RDS 성능 개선 해결책
- 캐싱 적용 (Redis 등) → DB 조회 요청을 줄여서 커넥션 점유 시간을 줄임.
- 쿼리 최적화 → EXPLAIN을 사용하여 실행 계획을 확인 후, 적절한 인덱스 추가.
- RDS 인스턴스 업그레이드
이러한 해결책 중 제가 개발한 API 문제에선 쿼리 최적화가 부족하다고 판단
쿼리 최적화 및 병목 현상 해결 과정
문제 쿼리 분석
문제 발생 쿼리
select g1_0.GATHERING_ID, b1_0.BOOK_ID, b1_0.AUTHOR, ... 생략, g1_0.START_DATE, g1_0.VIEW_COUNT from GATHERING g1_0 left join CHALLENGE c1_0 on c1_0.CHALLENGE_ID=g1_0.CHALLENGE_ID left join BOOK b1_0 on b1_0.BOOK_ID=g1_0.BOOK_ID left join IMAGE i1_0 on i1_0.IMAGE_ID=g1_0.IMAGE_ID where c1_0.START_DATE>='2025-01-20' and c1_0.END_DATE<='2025-03-30' and c1_0.READING_TIME_GOAL='ONE_HOUR' order by g1_0.CREATED_TIME desc limit 0, 10;
Explain Analyze 쿼리 실행 계획 분석
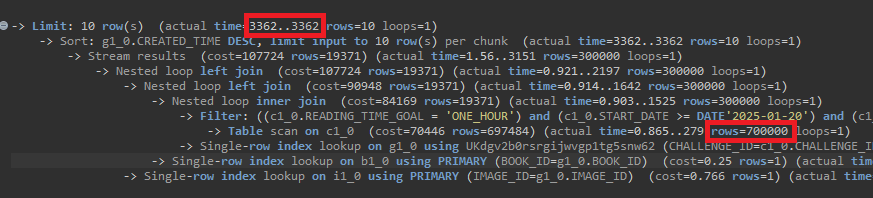
- 70만 데이터에 대해 Full Table Scan이 발생하며 응답 시간이 약 3362ms로 측정
- 응답시간(Latency) : 3362ms
문제 파악 및 최적화 접근 방식
원인
- 다수 테이블의 과다한 JOIN과 여러 필터링 조건으로 인해 Index가 적용되지 않았으며, Order By Sorting 또한 인덱스 기준에 부합하지 않았음
- 여러 필터링 조건에도 불구하고 무작정 JOIN을 수행하며 Index 순서 또한 지켜지지 않은 상황에서 풀테이블 스캔이 발생하였고, WHERE 조건의 인덱스 설정 순서와 OrderBy 조건이 부합하여 설정되지 않았기 때문
해결책
필터링 조건(챌린지 테이블 인덱스 설정 정보) 와 드라이빙 테이블인 모임 테이블을 우선적으로 조인 및 필터링/정렬/페이징 처리하여 모임 ID 리스트를 인덱스 스캔하고 해당 ID 리스트를 통해 Book, Image 와 같은 부가 정보를 2차 Join 쿼리 실행하여 사전에 페이징 처리 한 정보를 Sort하게 유도
개선된 API 테스트 측정 및 CPU, Memory 모니터링 결과
Throughput
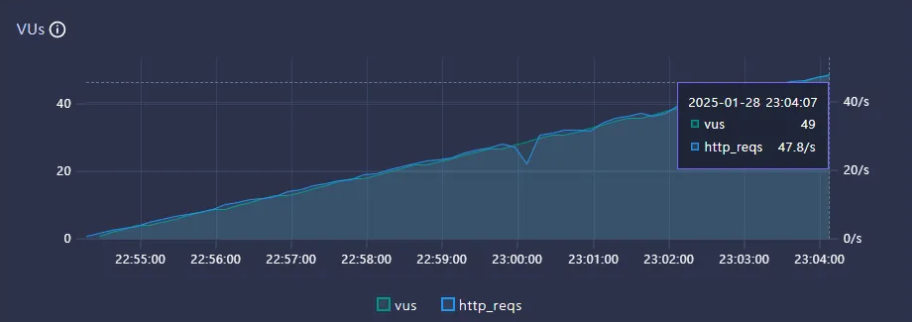
- VUs : 49
- 최적화 전 TPS : 1.2/s
- 최적화 후 TPS : 47.8/s
TPS 약 39.83배 증가. Scale Up/Out 및 캐싱 없이 단순 쿼리 최적화만으로 성능이 높게 향상된 것을 확인.
Latency

- 최적화 전 Latency : 46.3/s
- 최적화 후 Latency : 0 ~ 50/ms
HTTP Request Fail

요청 실패 수가 이전 결과에 비해 10배 감소하여 다소 안정적인 모습 확인.
CPU, Memory 모니터링 측정 결과
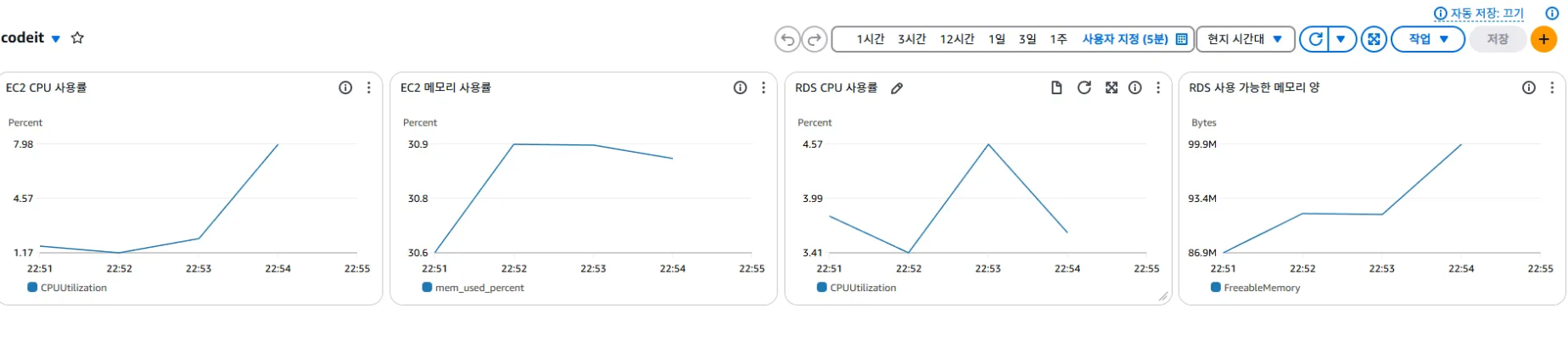
- 최적화 전 RDS CPU 사용량 : 약 99.4 %
- 최적화 후 RDS CPU 사용량 : 약 4.57 %
RDS CPU 사용률 90% 이상 감소.
마무리하며
이번 테스트를 통해 병목현상이 발생하는 원인을 구체적으로 확인할 수 있었습니다.
또한 단순히 캐싱 및 서버 스펙을 올리는 방법보다 DB 내부 인덱스가 어떤 방식으로 적용되는지 알아야 상황에 맞는 최적의 쿼리를 도출할 수 있다는 것을 파악하였습니다.