JPA Test 문제점과 헥사고날 아키텍쳐 개선 및 장단점
테스트를 작성하며 항상 느꼈던 것이 있습니다. 다음은 JPA를 사용한 간단한 테스트 코드 예제입니다.
1
2
3
4
5
6
7
8
9
@Test
public void orderDetail() {
Order order = orderService.createOrder("Smartphone", 1, 800.00);
Order result = orderService.getOrder(order.getId());
assertThat(result).isNotNull();
assertThat(result.getProduct()).isEqualTo("Smartphone");
}
이 코드는 주문을 생성하고 조회하는 기능을 테스트하는 것입니다.
그런데 이 테스트만으로 해당 기능이 정상적으로 작동한다고 보장할 수는 없다고 생각합니다.
우선, 테스트가 API의 작동을 보장해주는 조건을 생각해 보았습니다.
테스트가 보장해주는 조건
- 정확한 입력과 기대 결과
- 다양한 시나리오 테스트
- 데이터의 독립성
- 테스트의 일관성
이 중 가장 중요하게 생각하는 것은 테스트의 일관성이라고 생각합니다. 테스트 일관성이 없으면 동일한 코드가 실행될 때마다 다른 결과가 나올 수 있어 신뢰성이 떨어질 것 입니다.
이번 게시글에서는 테스트 일관성을 위하여 기존 테스트 방식에는 어떠한 문제점이 있으며 Architecture 개선 방안을 찾고 JPA와 같이 사용할 경우에 대한 장단점을 적어보고자 합니다.
개선 될 아키텍쳐를 위하여 Layered 아키텍쳐의 문제점을 설명했지만, Layered 아키텍쳐 또한 DIP를 적용하여 개선한다면 효과적이라고 생각합니다. 단지 헥사고날 아키텍쳐의 장점을 설명하기 위해 Layered 아키텍쳐의 단점을 강조하였습니다.
외부 라이브러리 의존 문제점
테스트 성공 조건
- JPA (사용한다 가정) 를 사용해야한다.
- SpringBoot (사용한다 가정) 가 띄워져 있어야 한다.
- 연결 가능한 DB가 존재해야 한다.
즉, 테스트가 성공하려면 이 세 가지 조건이 반드시 충족되어야 합니다. 이를 간단히 그림으로 표현하면 다음과 같습니다.
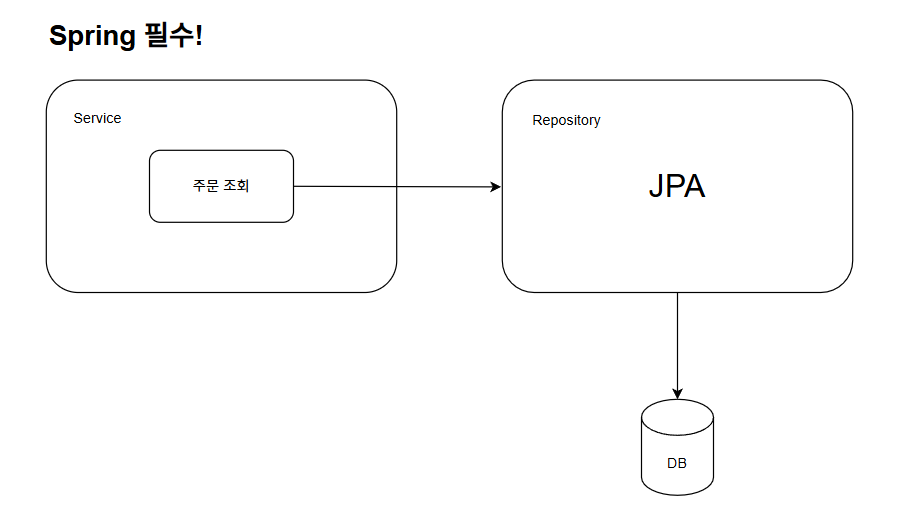
Spring Boot, JPA, DB 의존성을 가진 기존 아키텍쳐
문제점
- SpringBoot를 띄우는 시간이 너무 느리다.
- H2와 같은 DB를 띄워야 한다.
- 어제는 성공했지만 오늘은 실패하는 문제가 발생할 수 있다.
문제점으로 인해 우려 사항
- 알 수 없는 외부 라이브러리의 오류로 인해 잘 작동하던 코드가 회귀 버그를 유발하여 문제가 없는 코드를 디버깅하는 데 시간을 낭비
- 테스트 코드가 오히려 짐이 되는 상황이 발생
테스트의 목적과 TDD를 통한 유연한 설계
테스트는 단순히 성공과 실패를 검증하는 것을 넘어, 테스트하기 쉽게 만들어 유연한 설계를 도입하는 과정이라고 생각합니다. TDD(Test Driven Development)는 유연한 설계를 위한 테스트 방식으로 널리 알려져 있습니다.
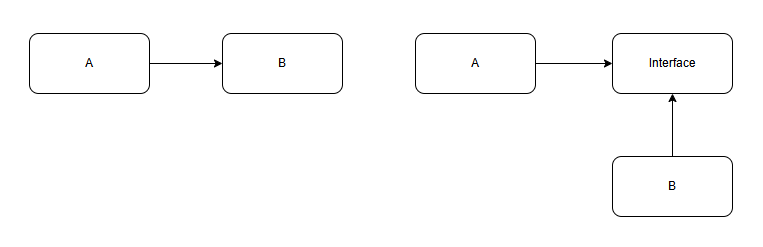
TDD를 도입하면, DIP(Dependency Inversion Principle) 를 통해 인터페이스를 사용하여 테스트하기 쉬운 유연한 설계를 도입할 수 있습니다. 또한 서비스 로직을 작성하기 전 테스트로서 검증하여 사전에 방지합니다.
DIP(의존성 역전)는 위 그림과 같이 A가 B에 직접적으로 의존하는 것이 아닌 Interface에 의존하게 됨으로서 테스트 시 A가 B객체로 테스트하는 것이 아닌 B를 대체할 구현체를 하나 더 생성하여 유연한 설계를 가져갈 수 있게 해주는 원칙입니다.
즉 불안함을 지루함으로 바꿔주는 것과 동시에 외부 의존 감소라는 효과를 TDD가 개발자에게 신호를 주겠지만, DIP로 Interface같은 고수준 정책에 의존하여 유연한 설계를 가져간다 해도 결국 DB에서 데이터를 가져와야 하는 문제는 변함이 없습니다.
Mock 프레임워크에 의존하는 것이 방법이겠지만 이는 테스트 상호작용의 대체제일 뿐이라 생각하며 확실한 신뢰성을 얻을 수는 없다고 개인적으로 생각합니다.
Layered Architecture 와 DB 중심 설계의 문제점
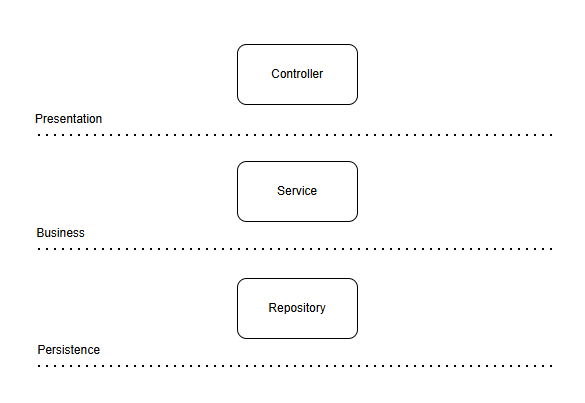
일반적으로 Layered Architecture를 사용할 때 데이터베이스는 필수적입니다. 특히, JPA와 같은 ORM을 사용하는 경우, 데이터베이스와의 상호작용을 최우선으로 고려하게 됩니다. 예를 들어, 주문 기능을 개발할 때 다음과 같은 흐름이 자연스럽게 형성됩니다.
- 상품 주문을 위하여 가져올 상품 정보가 꼭 필요하다.
- 주문이 어떻게 영속성 레이어에 저장되어야 할까?
- 저장되기 위하여 Entity는 어떠한 구조로 설계할 것인지?
이런 흐름은 결과적으로 데이터베이스가 필수적이라고 여겨지게 만듭니다.
이 접근 방식은 DB가 반드시 있어야 한다고 전제하는 문제점을 내포하고 있습니다. 이는 Layered Architecture가 데이터베이스 중심 설계를 유도 하기 때문이라고 생각합니다. 이 구조에서의 문제점을 간략히 정리하면 다음과 같습니다.
Layered Architecture 문제점
| Command | Description |
|---|---|
| DB 주도 설계 | 데이터베이스 스키마와 영속성 로직이 먼저 결정, 비즈니스 로직은 그 위에 얹혀짐. |
| 동시 작업이 불가능 | Repository가 구현되지 않으면 Service를 구현하기 어려워, 개발의 병렬 처리가 어려움. |
| 도메인이 죽음 | 도메인 로직이 Service에 집중되어 전체 도메인 모델이 한눈에 들어오지 않음. |
즉 Service는 모든 일을 하는 신과같은 존재이기에 객체에 대한 진지한 고민을 하지 않게 되고, 객체지향이 아닌 절차지향적인 개발로 이루어질 수 있습니다.
도메인과의 상호작용이 가장 중요하다.
사실, 영속성 레이어를 고려하기 전에 도메인과의 상호작용을 먼저 생각하는 것이 DDD와 RDD에 더 부합하고 캡슐화/응집도 강화에 이점이지 않을까 생각하며 데이터베이스는 그저 도메인 모델을 영속화하는 도구일 뿐, 비즈니스 로직을 주도하지 않게 된다고 생각합니다.
이러한 문제점을 극복하여 좀 더 쉬운 테스트와 유연한 설계로 이뤄지기 위한 개선 방안을 아래부터 적어보고자 합니다.
DIP를 통한 레이어 추상화 & 도메인과 Entity 분리를 통한 아키텍쳐 개선
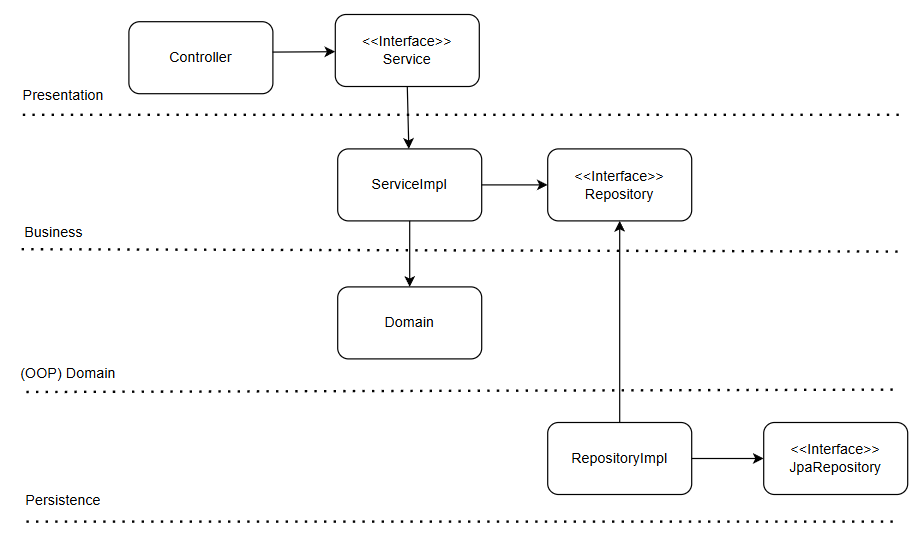
DIP 레이어 추상화 된 아키텍쳐
개선 사항
- 서비스 레이어에서 추상화된 Repository 인터페이스를 바라봅니다.
- JpaRepository에서 엔티티를 가져오는 작업은 RepositoryImpl이 담당합니다.
- 서비스 레이어에서는 엔티티가 아닌, 순수 도메인 객체만 다룹니다.
개선 전 Test 코드
1
2
3
4
5
6
7
8
9
10
11
@Test
public void orderDetail() {
/* 실제 엔티티 */
Order order = orderService.createOrder("Smartphone", 1, 800.00);
/* 실제 엔티티 */
Order result = orderService.getOrder(order.getId());
assertThat(result).isNotNull();
assertThat(result.getProduct()).isEqualTo("Smartphone");
}
개선 후 Test 코드
1
2
3
4
5
6
7
8
9
10
11
@Test
public void orderDetail() {
/* 순수 도메인 객체 */
OrderDomain order = orderService.createOrder("Smartphone", 1, 800.00);
/* 순수 도메인 객체 */
OrderDomain result = orderService.getOrder(order.getId());
assertThat(result).isNotNull();
assertThat(result.getProduct()).isEqualTo("Smartphone");
}

| 기존 방식 (엔티티 사용) | 개선 방식 (도메인 객체 사용) |
|---|---|
Order 엔티티 직접 사용 | OrderDomain 객체 사용 |
| JPA, DB 의존 | Spring 없이 테스트 가능 |
| @SpringBootTest 필수 | 일반 단위 테스트 가능 |
테스트 코드의 변화는 크지 않아 보이지만, Order가 OrderDomain으로 변화한 것뿐만 아니라, 외부 라이브러리를 사용하지 않고 Test Double의 Fake 객체로서 테스트가 가능하다는 것이 가장 큰 이점입니다.
테스트 시 서비스에서 순수 도메인 객체를 사용하면, DB 연결은 어떻게 해결할까?
기존에는 Spring Container를 띄워야만 Repository 의존성을 주입받아 DB에서 엔티티를 가져올 수 있었습니다.
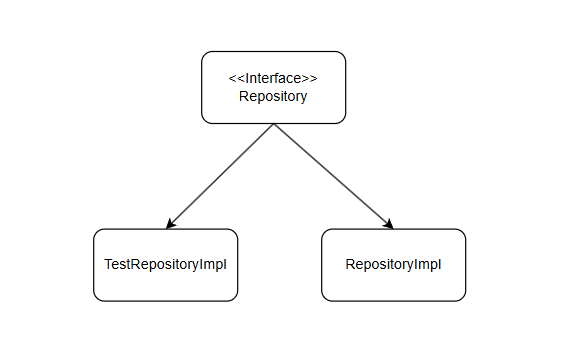
TestRepository Fake 객체를 사용하여 항상 일관된 데이터만 반환받는다.
하지만 개선된 아키텍처에서는 Service 레이어가 순수 도메인 객체만 다루고, Repository 인터페이스에 의존하도록 변경되었습니다. 따라서 테스트 시, 실제 시스템에서 사용하는 Repository 구현체 대신, 테스트 전용 Repository 구현체를 만들어 도메인 객체를 반환하도록 확장할 수 있습니다.
예시 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
class TestOrderRepositoryImpl implements OrderRepository {
private final AtomicLong autoIncrementId = new AtomicLong(0);
private final List<OrderDomain> data = new ArrayList<>();
@Override
public OrderDomain getOrder(Long orderId) {
return data.stream()
.filter(order -> order.getId() == orderId)
.findFirst()
.orElseThrow(...);
}
}
개선된 아키텍쳐로서 얻은 이점
- Spring Boot를 실행할 필요가 없습니다.
- H2와 같은 DB 연결이 필요 없습니다.
- 항상 일관된 테스트 결과를 보장합니다.
- 수백 개의 테스트를 수행해도 OOP 기반 테스트 덕분에 빠른 테스트 속도를 보장합니다.
실제 적용 사례
제가 최근 진행했던 팀프로젝트에서는 레이어드 아키텍쳐를 사용하였습니다. 아래는 그에 따른 테스트 코드의 예시입니다.
개선 전 모임 생성 테스트
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
@Test
@DisplayName("책, 썸네일 이미지, 유저 정보를 통하여 챌린지와 모임을 생성한다.")
@Transactional
void create() {
/* given */
final String username = "범고래1";
final LocalDate startDate = LocalDate.now();
final LocalDate endDate = startDate.plusDays(10);
final GatheringCreate gatheringCreate =
getGatheringCreate("모임 제목", "모임장 소개", startDate, endDate, 10, 20, 1L, RECRUITING, ONE_HOUR, ONE_WEEK);
final TestMultipartFile file = getTestMultipartFile();
/* when */
Gathering gathering = gatheringService.create(gatheringCreate, List.of(file), username);
/* then */
// 모임 ( Gathering )
assertThat(gathering.getId()).isNotNull();
assertThat(gathering.getName()).isEqualTo("모임 제목");
...이하 생략
}
개선 전 테스트 실행 결과
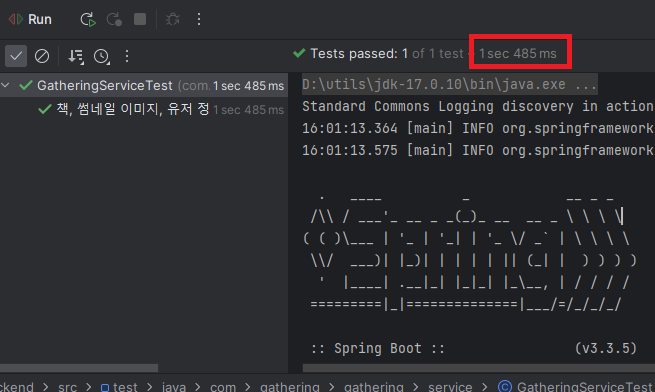
- 테스트 시간 : 1sec 485ms (1.485초)
- 사용된 외부 프로세스 - MySQL, Redis, AWS S3
위 화면과 같이, 스프링을 띄우고 외부 라이브러리와 연결하여 테스트를 실행하는 모습을 볼 수 있습니다.
하지만 이러한 외부 의존성들을 Mock으로 대체하더라도 결국 DB와 의존성 주입을 위한 스프링 부트는 필수적으로 로드됩니다.
개선 후 모임 생성 테스트
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
@Test
@DisplayName("책, 썸네일 이미지, 유저 정보를 통하여 챌린지와 모임을 생성한다.")
void createGathering() {
/* given */
final String username = "범고래1";
final LocalDate startDate = LocalDate.now();
final LocalDate endDate = startDate.plusDays(10);
final GatheringCreate gatheringCreate =
getGatheringCreate("모임 제목", "모임장 소개", startDate, endDate, 10, 20, 1L, RECRUITING, ONE_HOUR, ONE_WEEK);
final TestMultipartFile file = getTestMultipartFile();
/* when */
final GatheringDomain gathering = gatheringService.create(gatheringCreate, List.of(file), username);
/* then */
// 모임 ( Gathering )
assertThat(gathering.getId()).isNotNull();
assertThat(gathering.getName()).isEqualTo("모임 제목");
...이하 생략
}
개선 후 테스트 실행 결과
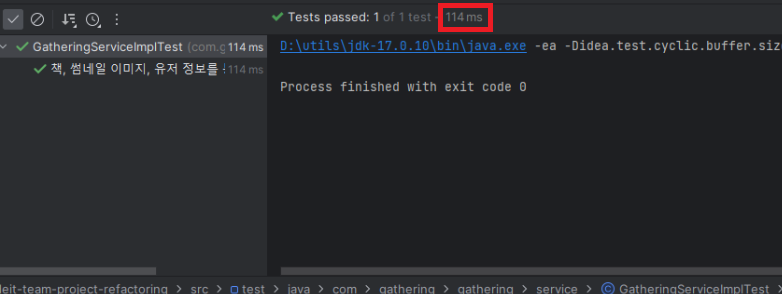
- 테스트 시간 : 114ms (0.114초)
- 사용된 외부 프로세스 - 없음
- [변경 사항] 의존성 주입 X -> Fake 객체
- [변경 사항] Gathering(Entity) -> GatheringDomain(Domain)
개선 전/후 성능 비교
- 개선 전 : 1sec 485ms (1.485초)
- 개선 후 : 114ms (0.114초) [92.32% 이상의 성능 단축]
외부 라이브러리와 의존성에서 벗어난 테스트를 작성함으로써, 테스트 속도가 92.32% 이상 단축되었고, 테스트의 일관성 또한 보장되었습니다.
특히 새로운 기능 개발 시 빠르게 Mock 객체를 생성하여 테스트 주도 개발(TDD)의 효율성을 극대화할 수 있었습니다.
헥사고날 아키텍쳐
헥사고날 아키텍쳐 개요
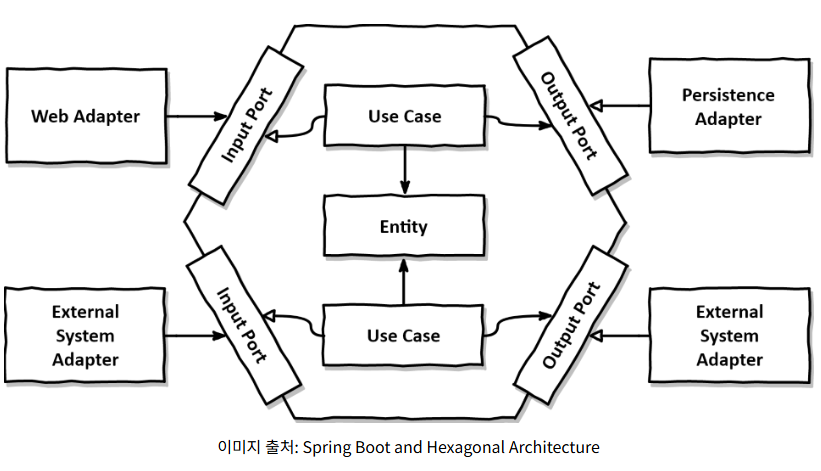
앞서 개선된 아키텍쳐가 곧 헥사고날 아키텍쳐의 형식과 비슷합니다.
이 아키텍처에서는 비즈니스 로직을 Domain, UseCase 에서 관리하며, 외부와의 상호작용을 Port와 Adapter를 통해 분리합니다.
- Repository는 Infrastructure 계층에 위치하여 데이터베이스와의 직접적인 연결을 담당합니다.
- Service와 Controller에서는 Port 인터페이스를 사용하여 Repository에 접근하므로, 구현체를 바꾸거나 테스트를 진행할 때도 비즈니스 로직을 변경할 필요 없이 유연하게 대체할 수 있습니다.
개선된 아키텍쳐를 헥사고날 아키텍쳐와 비교하기
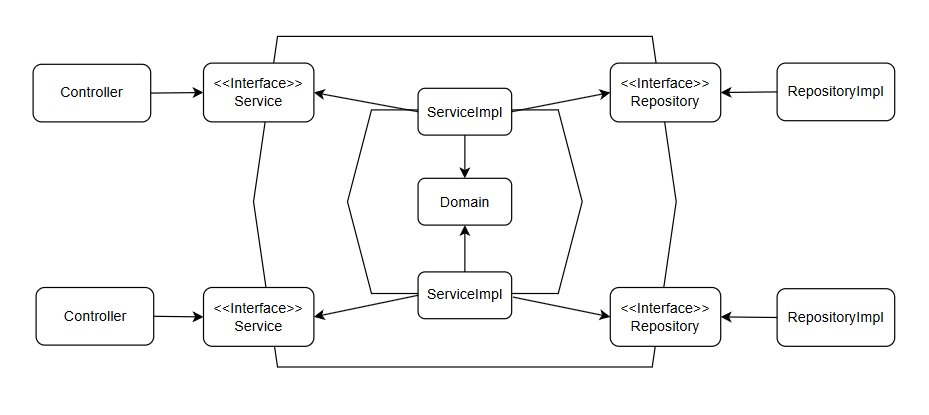
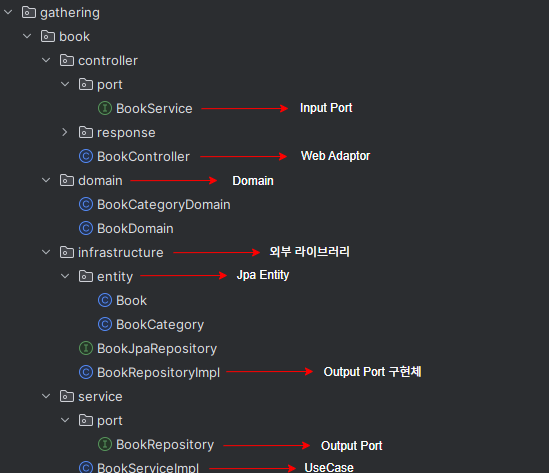
헥사고날 아키텍처는 애플리케이션의 핵심 비즈니스 로직을 외부 세계(사용자 인터페이스, 데이터베이스, 외부 시스템)와 분리합니다. 이는 도메인 중심 설계(DDD)와도 잘 맞아떨어지며, 유연하고 테스트 가능한 아키텍처를 구현할 수 있습니다.
이러한 아키텍쳐 구조가 과연 테스트에만 효과적일까?
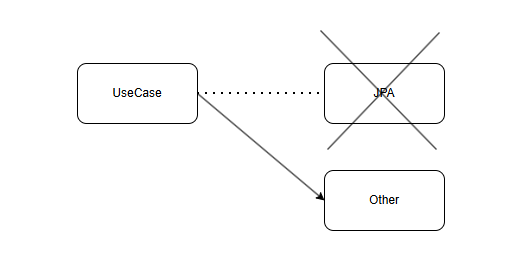
예시로 어떠한 스타트업에서 기존 Layered 아키텍쳐를 사용하여 JPA에 맞춰 설계를 진행했는데 JPA가 더 이상 업데이트나 지원을 안하게 되어 다른 방식의 영속성 레이어를 구현해야 한다면 이미 Service에 침투된 JPA의 Dirty 체킹과 Cascade 옵션으로 인해 많은 변경 사항이 발생할 것 입니다.
Layered Architecture
- 영속성 레이어 뿐만 아니라 비즈니스 레이어마저 모든 코드를 수정해야한다.
DIP를 잘 적용시킨 Layered Architecture 및 Hexagonal Architecture
- 비즈니스 레이어는 변함이 없으며 영속성 레이어만 수정하면 된다.
JPA 사용과 헥사고날 아키텍처 도입 시 발생하는 문제점 (은탄환은 없다)
1. JPA의 편리함을 일부 포기해야한다. ( Dirty Checking )
JPA에서는 엔티티를 영속성 컨텍스트에서 관리하며, Dirty Checking을 통해 엔티티의 변경 사항을 자동으로 감지하고 데이터베이스에 반영합니다. 그러나 헥사고날 아키텍처를 도입하면 이를 포기해야 하는 상황이 발생합니다.
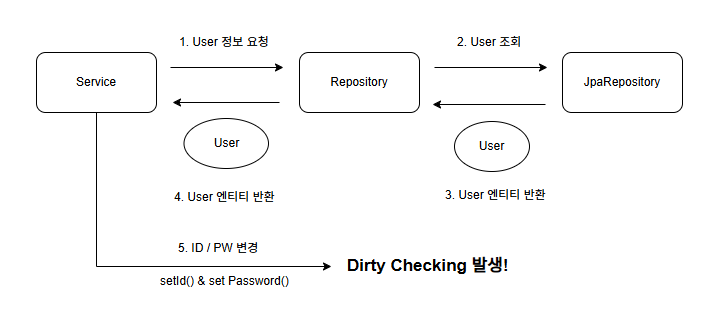
Dirty Checking 활성화 : 영속성 컨텍스트에서 관리하는 Entity를 수정하였기 때문에 Dirty Checking 발생
위 이미지 처럼 도메인 객체를 다루지 않았더라면 기본적으로 JPA의 Dirty Checking 으로 인하여 자동으로 Update가 발생하였을 것 입니다.
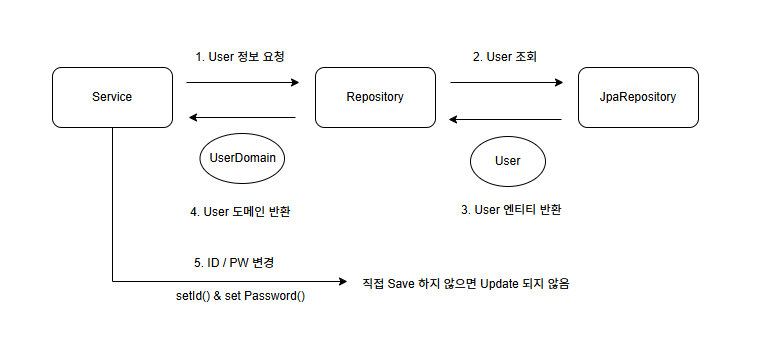
Dirty Checking 비활성화 : Repository -> Service 간 Entity -> Domain 매핑으로 인해 영속 -> 준영속 상태로 변경된다.
헥사고날 아키텍처에서는 SRP(단일 책임 원칙)를 준수하기 위해 Repository가 데이터베이스 접근만을 담당합니다. 따라서 Repository에서 Service로 데이터를 전달할 때 Entity를 DTO로 변환해야 합니다.
그런데 Service 단에서 DTO를 수정해도 이는 매핑으로 인해 영속성 컨텍스트에서 빠져나간 준영속 상태의 객체이기 때문에 Dirty Checking이 동작하지 않습니다. 아래는 관련 코드 예제입니다.
1
2
3
4
5
6
7
8
9
10
11
@Override
public UserResponse update(UserUpdate userUpdate, MultipartFile file, String username) {
UserDomain user = userRepository.findByUsernameWithImage(username);
ImageDomain image = file.isEmpty() ? user.getImage(): uploadImage(file, user.getProfile());
user = user.update(userUpdate, image, passwordEncoder);
UserDomain saveUser = userRepository.save(user);
String accessToken = generateTokenAll(username);
return UserResponse.fromEntity(saveUser, accessToken);
}
위 코드를 보면, user.update()로 도메인 객체를 수정했지만, Dirty Checking이 작동하지 않으므로 변경 사항을 수동으로 저장(userRepository.save())해야 합니다. JPA의 Dirty Checking을 사용할 수 있다면, 저장을 명시적으로 호출하지 않아 도 됩니다.
Dirty Checking 비활성화의 장단점
단점
- 수동으로 변경 사항을 저장해야 하므로 코드가 장황해지고 관리해야 할 부분이 증가합니다.
장점
- 데이터 변경이 어디서 이루어졌는지 명시적이고 직관적으로 알 수 있습니다. 이는 예상치 못한 데이터 수정으로 인한 문제를 예방할 수 있는 장점이 있습니다.
2. JPA의 Cascade 포기
문제 상황: Cascade 설정의 무력화 JPA에서는 연관관계를 가지는 엔티티에 CascadeType.ALL을 설정하면 부모 엔티티를 영속화할 때 자식 엔티티도 자동으로 영속화됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
@Getter
@Entity
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Gathering {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "gathering_id")
private Long id;
@OneToMany(mappedBy = "gathering", cascade = CascadeType.ALL)
private List<GatheringUser> gatheringUsers = new ArrayList<>();
}
위와 같은 엔티티 구조에서는 아래와 같이 부모 엔티티를 저장하면서 자식 엔티티도 자동으로 저장됩니다.
1
2
3
4
5
6
7
8
9
10
@Override
@Transactional
public void join(Long gatheringId, String userName) {
User user = userRepository.findByUsername(userName);
Gathering gathering = gatheringRepository.findByIdWithGatheringUsersAndChallenge(gatheringId);
gathering.join(user, gatheringValidator); // 부모와 자식 관계 설정
gatheringRepository.save(gathering); // Cascade를 통해 자식 엔티티도 영속화
}
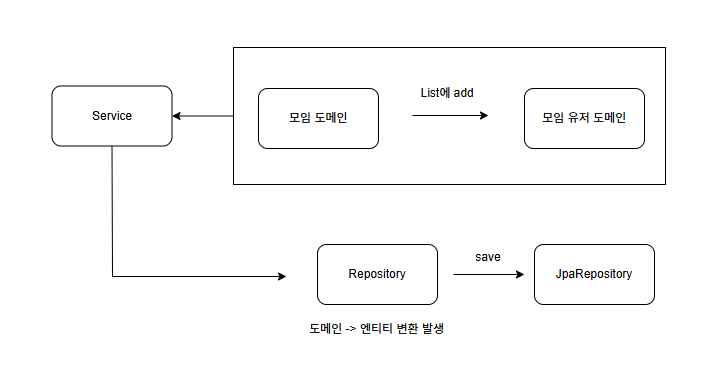
영속성 컨텍스트 Entity가 아닌 Domain List에 add한다.
하지만 헥사고날 아키텍처를 도입하면, Service에서는 도메인 객체를 사용하고 Repository에서 이를 엔티티로 변환해야 합니다. 이 과정에서 영속성 컨텍스트에서 빠져나갔거나 애초에 없었던 준/비영속 상태의 엔티티를 사용하기 때문에 Cascade 설정이 무효화됩니다.
1
2
3
4
5
6
7
8
9
10
11
@Override
@Transactional
public void join(Long gatheringId, String userName) {
UserDomain user = userRepository.findByUsername(userName);
GatheringDomain gathering = gatheringRepository.findByIdWithGatheringUsersAndChallenge(gatheringId);
gathering.join(user, gatheringValidator); // GatheringUser 추가
gatheringRepository.save(gathering); // 부모 저장
gatheringUserRepository.save(GatheringUserDomain.create(user, gathering)); // 자식 저장
}
이처럼 부모-자식 간 저장이 분리되면서 모든 저장 작업을 명시적으로 처리해야 합니다.
JPA 의 편리함을 포기하면서 까지 헥사고날 아키텍쳐를 도입해야만 할까?
1. 명시적 코드로 인한 직관성 증가
헥사고날 아키텍처를 도입하면, Dirty Checking 및 Cascade 설정을 사용할 수 없어 추가적인 코드 작업이 필요합니다. 하지만 이러한 명시적인 코드는 데이터가 언제, 어디서, 어떻게 수정되었는지 직관적으로 이해할 수 있게 합니다. 이는 유지보수성과 신뢰성을 증가시켜줍니다.
2. 영속성 전이에 대한 불안감 해소
Cascade를 사용하는 경우 의도치 않게 데이터가 삭제되거나 저장되는 등의 문제가 발생할 수 있습니다. 이를 명시적으로 처리하면 이러한 불안감을 해소할 수 있습니다.
3. 편리함 -> 명확함
JPA의 Dirty Checking과 Cascade는 매우 편리한 기능이지만, 헥사고날 아키텍처에서는 이를 포기해야 하는 경우가 종종 발생합니다. 그럼에도 불구하고 헥사고날 아키텍처의 명확한 코드 작성과 유지보수의 용이성은 충분히 이를 도입할 가치가 있습니다.
결론적으로 헥사고날 아키텍처는 단순히 트렌드를 따르는 것이 아니라, 소프트웨어 설계의 원칙과 유지보수성을 극대화하기 위한 전략임을 명심해야 합니다.